Here at Aurora Solar, we take roof modeling very seriously. We even have a dedicated team of highly trained designers who support our customers with on-demand roof models via our Expert Design Services offering, and we’re always looking to improve.
Our team created our own artificial intelligence (AI) and computer vision models after years of creating models. Today, our customers leverage these powerful AI capabilities using Aurora AI.
Just for fun — and, to help improve our understanding of generative models more generally — we’ll explore generative adversarial networks (GANs) vs. diffusion models in today’s blog post.
Key takeaways:
- GANs and Diffusion Models compete in generating realistic roof images from input labels.
- Diffusion Models surpass GANs in realism but require significantly longer runtime.
- Future integration of diffusion models holds promise for improving roof-modeling pipelines.
A bit of background
Over the years, we’ve gathered insights from over half a million roof images meticulously modeled by our Expert Design Services team, including labels for each roof face, tree, and obstruction — including vent pipes, skylights, and others.
For each roof, we have labels that look like these:
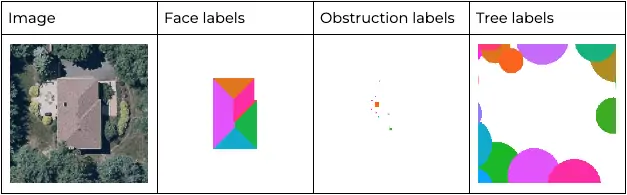
Using this comprehensive database of highly accurate training data, our team has developed and deployed our own AI and computer vision models.
Today, our customers simplify roof design by using Aurora AI. For any site entered into the system, our roof modeling pipeline takes the roof images and LIDAR data as input to automatically output 3D roof models for our customers.
To help improve our understanding of generative models more generally, we can also investigate the inverse problem: Can we take the labels as inputs and generate a realistic roof image?
In the field of computer vision, this problem is known as image generation. Historically, this problem has been tackled by generative adversarial networks (GANs). But now another new type of network, called diffusion models, is an option for image generation tasks — and these models exceed the performance of GANs.
Problem statement
The task we’re investigating is conditional image generation: Given roof face, obstruction, and tree labels generate a realistic image of the roof.
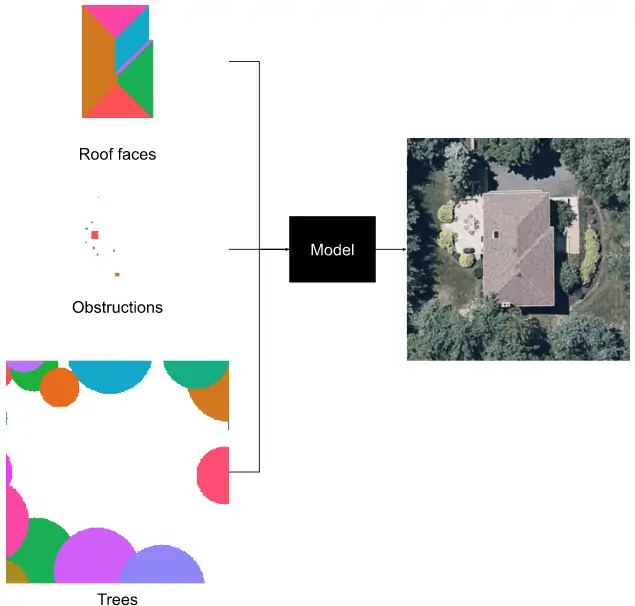
How a GAN is trained
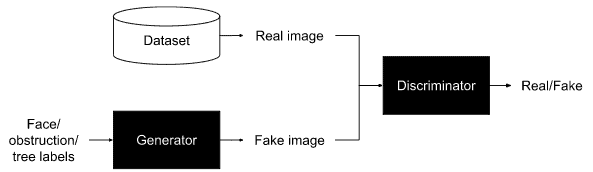
A generative adversarial network works by training a pair of networks: a generator and a discriminator. The generator is the network that generates the fake images. The discriminator, on the other hand, is a classification network that looks at an image and classifies whether it is real or fake. Both networks are trained simultaneously, with the discriminator trying to classify real and fake images correctly and the generator trying to fool the discriminator into classifying its fake images as real.
As the discriminator improves at telling apart real and fake images, so do the images the generator produces. (NOTE: The number of training epochs is the number of times a model works through the entire dataset. Each epoch, the model sees every image in the dataset once.)

Pros and cons of generative adversarial networks
GANs have transformed the field of artificial intelligence by generating new, synthetic instances of data that are indistinguishable from real data. However, they’re not perfect. Below are some of the biggest advantages and disadvantages to using GANs for image generation.
Pros of GANs
- Strong ability to generate high-quality, realistic images, videos and voice recordings.
- Contribute significantly to image enhancement and content creation.
- Facilitate unsupervised learning, allowing for the discovery of patterns without labeled data.
Cons of GANs
- Require substantial computational resources and expertise to train effectively, making them less accessible.
- The realism of generated content can be a double-edged sword, leading to ethical concerns such as creating deepfakes.
- May struggle with mode collapse, where the generator starts producing a limited variety of outputs, undermining the diversity of generated data.
How a diffusion model is trained
Conversely, to train a diffusion model, we first take an image and gradually add noise to it over many steps until it is indistinguishable from an image of pure noise:

Then, the network is trained to perform the reverse process: it predicts a slightly less noisy image given a noisy image at each step.

By repeatedly applying the diffusion network to its own predictions, we can go from an image of pure noise to a realistic noiseless image.
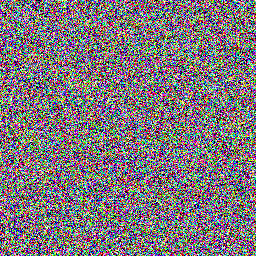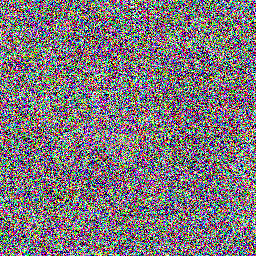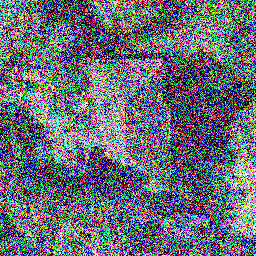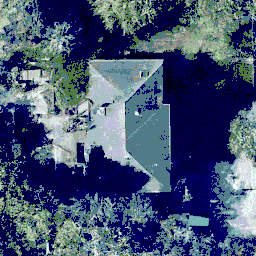
Pros and cons of a diffusion model
Diffusion models have gained a lot of attention in the AI field for their ability to generate highly detailed and coherent images, video, and audio. But with their advantages come disadvantages as well:
Pros of diffusion models
- Capacity for producing high-quality outputs that often surpass GANs in terms of realism and diversity
- Skilled at handling complex distributions, making them versatile for various applications.
- A more reliable training process than GANs, avoiding the issue of mode collapse.
Cons of diffusion models
- Require significant resources for training and generation, which can limit accessibility.
- Generating data through iterative denoising is much more time-consuming compared to direct generation methods used by GANs.
GAN vs. diffusion model: results
Here is a comparison of outputs from each method:
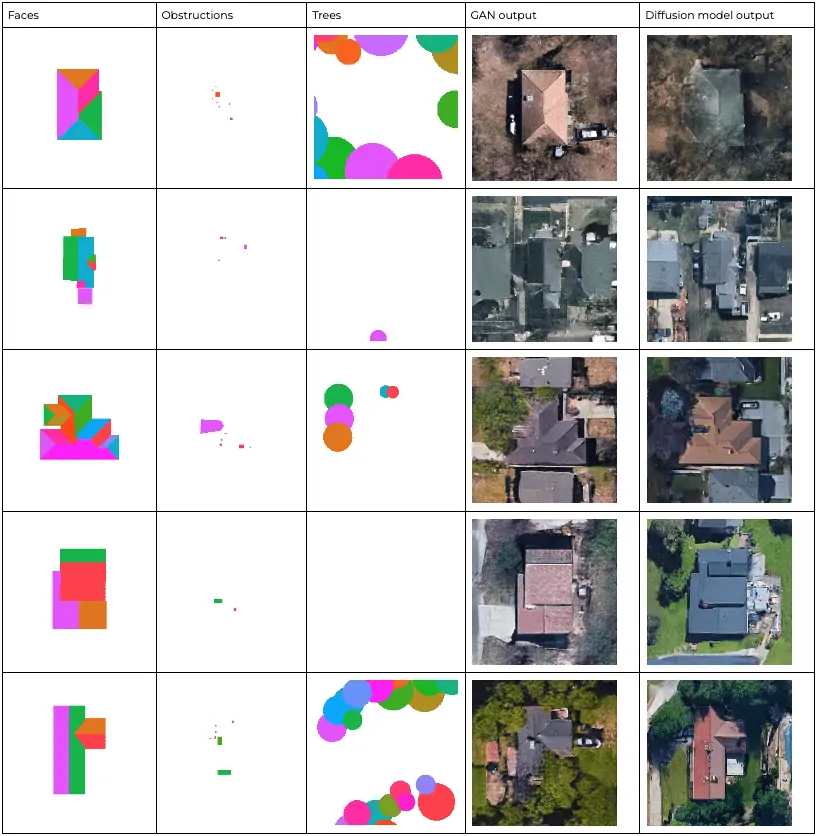
As you can see, the diffusion model’s outputs are better and more realistic. The GAN outputs have visible unrealistic artifacts, and neighboring buildings are not modeled as realistically as well.
Using the Frechet inception distance to measure realism
The Frechet inception distance (FID) is a common metric used to evaluate the realism of generated images. The lower the score, the better and more realistic the images are. After about seven days of training*, the GAN achieved an FID of 40.2, while the diffusion model achieved 31.3, meaning that the images generated by the diffusion model match the distribution of real images better than the GAN’s. These metrics corroborate what we see in the images above.
(* Each model was trained for seven days on an NVIDIA A100 GPU.)
Runtime
One drawback of diffusion models is that they take much longer to generate images than GANs. For instance, it takes our GAN about two minutes to generate 4,000 images, while it takes the diffusion model two days to do the same. This is a speed difference of more than 1,000x! Having said that, one is able to trade runtime for image quality with the diffusion model by using fewer denoising steps. For example, if we want to generate images 40 times faster with the diffusion model, then the FID increases from 31.3 to 55.9.
How the models respond to input changes
One other thing we were curious about was how the models would respond to changes in the input. We moved an obstruction across the image, and this is how each model’s output changed.
Here’s the moving obstruction input:
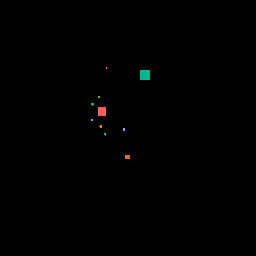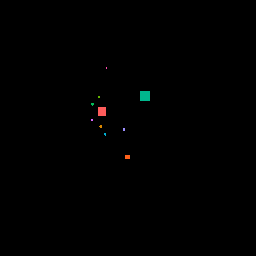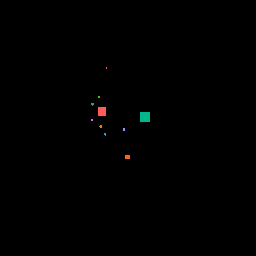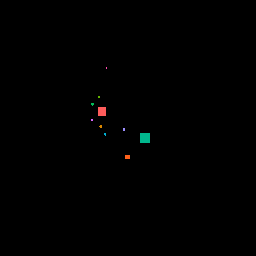
Here’s how the GAN output changed:

And here’s how the diffusion model output changed:

We can see that the GAN’s outputs are a lot more unstable than those of the diffusion model, which makes for a more interesting GIF, but suggests that the generation is a lot less controllable. The diffusion model’s outputs hardly change except for the moving obstruction itself, whereas the entire GAN image changes as the obstruction moves.
Why it matters
To provide some background, we have a dataset of hundreds of thousands of roofs that we trained these generative models on. We’ve seen the different results of different generative models (both GANs and diffusion models) above. Our roof-modeling pipeline, which takes roof images and LIDAR data as input and automatically outputs 3D roof models, is trained on the same dataset.
Secondly, diffusion models were invented for the purpose of generating realistic images, and are currently primarily used for that. But our team is looking into whether they could be used to improve the results of our roof-modeling pipeline as well.
Conclusion
As computer vision literature and our own findings suggest, diffusion models can indeed produce realistic images that match and even outperform GAN-generated images. However, diffusion models take much longer to generate images than GANs.
Over the next few years, we will hopefully see developments that speed up the generation of images with diffusion models.
Acknowledgments
Many thanks to Maxwell Siegelman for implementing and training the diffusion model. Thanks as well to Sherry Huang for her feedback on this blog post.
FAQs GAN vs diffusion model
How fast is a GAN compared to a diffusion model?
GANs are generally much faster than diffusion models when generating images, because GANs use a generator and discriminator network to generate images, while diffusion models require multiple iterations of a diffusion process for each image.
For example, our GAN takes about two minutes to generate 4,000 images, while the diffusion model takes two days to do the same. This is equivalent to approximately 0.03 seconds and 40 seconds respectively per image, or a speed difference of more than 1,000x.
Is diffusion better than GANs?
It really depends on which application you’re using and for what. Diffusion models may be best for tasks valuing high-quality, realistic outputs and diversity. But in situations where computational efficiency is important, GANs might be preferred. Ultimately, to decide between diffusion models and GANs, you should carefully consider the project’s objectives, available resources, and the specific challenges that each technology best addresses.
Why do diffusion models not suffer from mode collapse?
Mode collapse is a phenomenon where the generator produces limited or repeated samples. This is more likely to happen with GANs if the generator finds a particular pattern or subset of the data that consistently fools the discriminator. Unlike GANs, diffusion models are less prone to this issue because they use an iterative refinement process that gradually improves the generated images, rather than attempting to produce them all at once. Diffusion models also don’t rely on a discriminator to guide the generator, which further minimizes mode collapse risk.
References and further reading
- Improving Diffusion Models as an Alternative To GANs, Part 1 | NVIDIA Technical Blog
- [2006.11239] Denoising Diffusion Probabilistic Models
- What are Diffusion Models? | Lil’Log
- Introduction to Diffusion Models for Machine Learning
Featured image courtesy of Project Sunroof.


