Today we rely on (and take for granted) a lot of amazing technological achievements that would’ve seemed like magic just a few decades ago. We can finish up a work document on our phone while traveling 500 miles per hour at 30,000 feet. And the USB-C charger you use to charge that phone? It has more computing power than the computers that helped astronauts go to the moon.
In the solar industry, LIDAR — planes (or drones) flying over vast areas of the country, bouncing laser beams off structures and the ground to determine their heights — is one of those things, and it has become one of the critical technologies installers rely on to generate accurate designs. In this blog we’re going to explain a bit more about how we use LIDAR at Aurora to help make your design process quicker and easier, and we’ll also share some exciting news about our updated LIDAR data.
LIDAR’s Role at Aurora
At Aurora, we use LIDAR data to calculate building heights, roof slopes, and tree heights. In turn, we use these calculations to power our NREL-validated irradiance and shading analysis — so you can get them right from your Aurora app, rather than making time-consuming site visits. LIDAR is a powerful tool that we use in products like Design Mode and Sales Mode, so you can do things like calculate irradiance and energy offset at the click of a button. It’s also a critical part of Lead Capture AI and Aurora AI, helping to rapidly generate roof models for customers and designers alike.
But where do we get our LIDAR data from? Unlike other solutions that may only rely on one map imagery or LIDAR provider, we use a network of providers so we can be confident that every project uses the most accurate data. Some of our sources are public agencies, like The National Oceanic and Atmospheric Administration (NOAA) and The United States Geological Survey (USGS), who capture LIDAR data for a variety of reasons, including measuring damage after natural disasters like earthquakes and forest fires and mapping areas for potential mineral resources. By combining multiple reliable sources into one proprietary Aurora database, we’re able to deliver highly-accurate shading and performance simulation for our customers.
What’s New
Because of the important role LIDAR plays, our customers need to have the most up-to-date data whenever they work on a solar project. To make sure this happens, we have a dedicated geospatial team that continuously monitors and enhances the underlying data that powers Aurora’s industry-leading accuracy. So, when we found out that USGS had released new data from 2019, our team was ready to perform an essential update.
Updating our LIDAR data to include the new USGS data did a couple important things: it introduced new coverage and it refreshed old coverage. We also wanted to provide more accurate data with higher resolution and point density, which is the amount of measurements taken per area.
Overall, the LIDAR update resulted in:
- Refreshing roughly 1.8 million square miles across the United States
- Updating the average year of data to 2018 (ranging between 2011 and 2021) from 2010 (ranging between 1996 and 2018)
- Increasing the point density from 9.2 points per square meter to around 12.8 points per square meter
- Increasing coverage from 95.79% to 98.26% of the US population
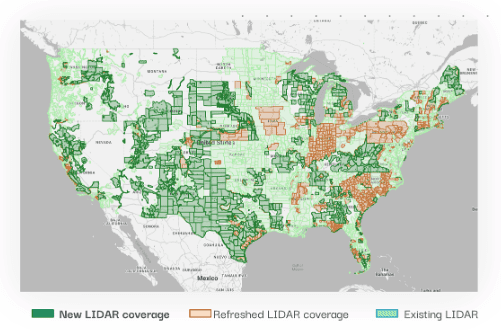
In 2018, Aurora’s LIDAR covered 95.79% of the US population. After the LIDAR refresh, 98.26% of the population is now covered by Aurora’s LIDAR.
To explore our LIDAR coverage for yourself, check out this map:
(Map not showing up? Click here to explore.)
Key Challenges to Solve
Tackling a task as large as this LIDAR update wasn’t easy. There were a few key challenges to address.
First, adding and storing a huge amount of LIDAR data was a tremendous task. The new data more than doubled our previous database size to over 280 terabytes—adding 180 terabytes to the almost 101 terabytes of the original dataset. This data came in many files, which could be inconsistent with how elements such as point density, coordinate system, and boundaries in the files were labeled. The files themselves were also inconsistent in size, ranging from 1-2 megabytes to 2 gigabytes.
In addition, there was overlap from the original LIDAR data sources, so it was important to pick the newest dataset for any given area.
Another challenge was setting up fast access to the LIDAR data from the Aurora app. We want LIDAR to load in seconds for any project, but since there is so much LIDAR data, simply scanning through all the files would mean it would take minutes for data to show up in the Aurora app.
Finally, if the LIDAR files covering a certain site were too small, they would have to be merged together with other files to cover the larger area, which requires time to download and crop. On the other hand, if one file covers too large of an area, you would have to crop and find the points that actually cover the house property. Cropping and downloading on both ends could take a long time. Making the correct tradeoff between not overcomplicating the database with too many files and optimizing download time was a key concern.

To effectively use LIDAR and map imagery in our products, and give customers a great user experience, we had to address all of these challenges. And we had to do this while maintaining the level of current data availability and reliability you rely on.
LIDAR update process
We can break the LIDAR update process down into four steps:
1. Download and cache the new LIDAR datasets.
2. Split the data into tiles.
3. Verify the usability of data. Manually check that each dataset is correct.
4. Migrate verified data into production.
While these steps seem relatively simple by themselves, our main challenge was repeating this for 180 terabytes of new LIDAR data.
Downloading new LIDAR
As we download the data, we verify that the LIDAR file is properly formatted, extracting the useful metadata to a database. Some examples of useful metadata are the number of points, the coordinate reference system, and the boundary of all the points — any files missing these fields are marked as invalid.
Invalid LIDAR files are not processed any further, as they could cause unexpected errors in our pipelines, or worse, pass inaccurate data into production. Other extreme examples of invalid files include files with no data or files with malformed metadata.
Splitting the files
Splitting the files helps us make sure that project designers can access these LIDAR points in Aurora in a reasonable amount of time.
Any given LIDAR file can cover anywhere from a few square meters to hundreds of square miles. This means that a single project location might be composed of dozens of tiny LIDAR files or a single huge LIDAR file. To guarantee that LIDAR for any project loads in a reasonable time, we reorganized the LIDAR points into millions of small tiles.
A tile is just a square area on the map. Chopping up the map of the entire world into trillions of tiles guarantees that a project’s bounding box is within a single tile, in the best case, or 4 neighboring tiles in the worst case. Another benefit of reorganizing the datasets into this tile format is that if newer LIDAR data is added, we can simply replace the old tile with the new one, because the bounding box is the same.
So, the splitting step for a dataset is done by cropping or merging all of its original LIDAR files into a series of neat and consistent square tiles.
Verifying the data
With all our datasets in this tile format, we complete a final QA verification to filter out the few datasets that are not useful or incorrect. At this point, we need to review and revise:
- Datasets with mismatching metadata
- Regions without buildings
For example, some datasets have incorrect height units where the points are listed in feet, but the actual unit is supposed to be meters. We take sample tiles from each dataset and manually inspect them to make sure that they don’t have any of these anomalies.

You can see that the roofs in this project are very steep. This is caused by the fact that although the LIDAR files stated that the units were in meters, the actual points were listed in feet, which caused the points to map much higher than in reality. When this happens, we need to manually rescale the points from feet to meters before deploying to production.

In the picture above, the LIDAR points are significantly off center from the building. When this happens, we have to manually realign it because our algorithms can only automatically align LIDAR that are less than 10 meters off.
Since some of the LIDAR datasets were collected for survey reasons, these datasets do not contain any buildings, so they are removed from our production dataset.
Deploying the data to production
The final step in this process is to deploy the tiles for our services to access. Of course, it’s not as simple as replacing all the old tiles with new ones; we want to select and deliver the best option for project designers based on both time and quality.
We based our selection criteria on point density and age of the dataset that the tile originated from. For reference, a point density of 0.7/m2 is acceptable, and a point density of 4 or more is quite good. And of course, newer data is always more preferable.

In closing…
Since LIDAR is such a huge part of many installers’ sales and design process, we wanted to make sure to let you look under the hood and see how it goes from a plane shooting lasers to something you quickly and easily access via your Aurora app. If you have any questions that we didn’t answer here, or you’d simply like to learn more, please reach out for a personalized demonstration.
While a lot of work went into this LIDAR update, we hope you’ll eventually come to take it for granted, just like watching a movie on your cell phone on a plane’s WiFi.


